



Key Takeaways:
- Java is made of threads: many of the internals of JVM programs rely on threads from debugging to GC
- The classical threads are expensive as they are just thin wrappers around OS threads
- Various solutions appeared through the years from the executor framework, fork/join pool, reactive streams and the latest Project Loom and its virtual threads
- Parallel usage of resources is very helpful, but misused can make your program expensive
Java has been around for over two decades, and it has been and continues to be a dominant force in the software development arena ever since. There are multiple reasons why it is doing so well, however, one of which is concurrency. Java started its journey by introducing an in-built threading model.
In this article, I will go over a bit of history, how it shaped our programming understanding and practice using Java, where we are now, and one particular problem with it.
This will be a bit long, but I’m sure you will enjoy it.
Let’s begin the journey!
Java is made of threads:
From day zero, Java introduced threads. Threads are the basic units of execution in Java. This means that any Java code we want to run is executed by a thread. Threads are an independent unit of the execution environment on the Java platform.
From this, it’s easy to see that if a program has more threads, it has more places where code can be run. That means we can do more things simultaneously. That brings many benefits to the table. One particular benefit is that it improves the application’s throughput by utilizing all the resources available on the machine. By doing so, we can achieve more from a program.
Threads are in all layers of the Java Platform:
Not only does the thread execute code, but it also keeps track of the invocation of methods in its stacks. So when a Java program runs into trouble while executing, we get an exception. The exception contains the stack trace, from which we can figure out what went wrong. So we can tell that threads are a means of getting those stack traces.
Besides, we use threads if we need to debug our program through the IDE. We need threads if we need to profile our program or parts of it. Java garbage collectors run in a separate thread. All of these point out that concurrency, or “threads,” is an integral part of the programming platform.
However, threads are expensive:
In modern Java web applications, throughput is achieved by using concurrent connections. Usually, a dedicated thread is given to every request from a client. Modern operating systems can handle millions of concurrent connections. This indicates that we will have more throughput if we have more concurrent connections.
The conclusion may seem legit; however, the reality is far from it. The reason is that we cannot create as many threads as we want to accomplish that.
Threads are limited and expensive. Creating a thread takes 2 MiB of memory outside of the heap. The other thing we must remember is that, traditionally, Java threads are just a thin wrapper around an operating system’s threads. And we can only create a few of them. Even though we can get a good amount of them, we cannot always guarantee the application’s overall performance. So the content switch has a cost associated with it.
You can test the following program and see how many threads you can create.
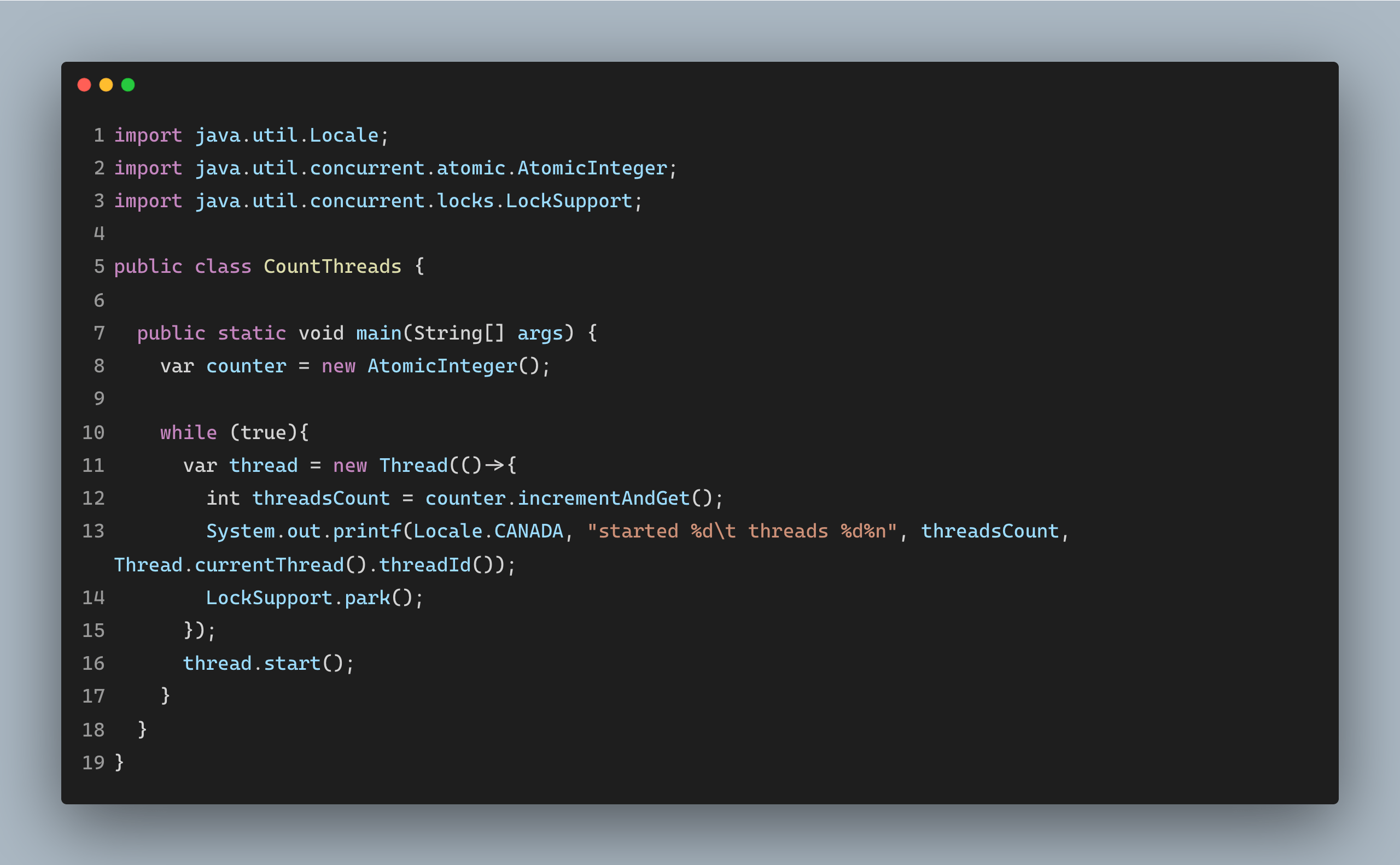
So far, we’ve discussed why Java threads are essential and some of their limitations. So, let’s dig a bit further.
What problem do we have now:
Modern software application development requires high data scale, as we need to deal with too much data. We have high usage as well. That brings us to the cost associated with it. Cloud computing costs can quickly be accumulated if we are not careful.
We have already established that creating threads is not cheap, and they are limited in number, so we cannot afford to waste any of them. Instead, we need to use their full capacity; however, in reality, that’s not what happens. In the traditional programming model, it blocks the current threads when we call something that takes time to respond. For example, if we make a network call—it could be a microservice or a database call—the thread we are using to invoke the call gets blocked until we get the results. While waiting for the results, the thread does nothing, basically sits idle, and wastes valuable resources, resulting in cloud bills for no good reason.
So from the postulation mentioned above, we can conclude that blocking calls isn’t good for us.
Let’s see an example-

In the above code, we do make five method invocations. Let’s assume all of them require some time to process. For simplicity, let’s say they all take 200 milliseconds to process.
Since we are making all the calls one after another, we will require at least 200 * 5 = 1000 milliseconds to complete this method. Therefore, the thread that started all these invocations must wait for them to finish.
From the scenario, we see that the thread that invokes the calculateCreditForPerson() method is blocked most of the time since it’s waiting for the subsequent methods to be finished. While it’s blocked, it’s not doing anything. Basically, its resources are being wasted by not being able to do anything.
The question is, how can we improve it?
There have been several attempts to gradually improve the situation so that threads don’t get blocked in such a scenario. I will start from the very beginning of the history of Java.
Classical implementations:
The method invocations inside the method of the above code are not all dependent on each other. So, for example, the second, third, and fourth invocations can be done in parallel to each other. If these three methods get executed in parallel, we can make some improvements. The invoker thread would then take less time, which means less blocking time. That’s a huge improvement.
We don’t have a solution for the blocking problem here, but the main thread responsible for invoking this method stays blocking far less time. It would have more time to work on something else using those time.
So how would we implement this classically?
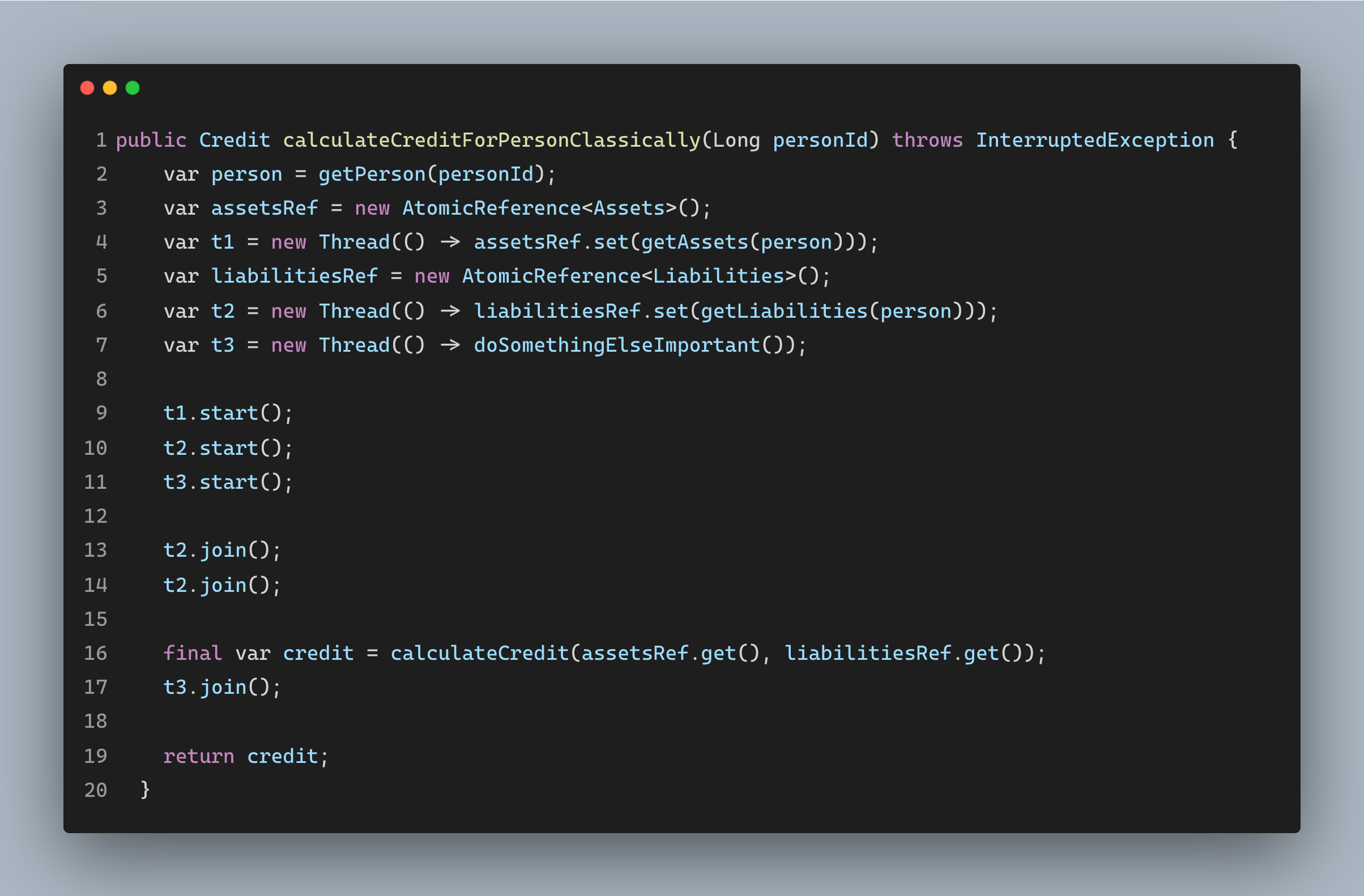
We will end up with something like the above. We will create a new thread on an ad hoc basis and store the result in an AtomicReference.
This is fine, but we have no control over how many threads we want to create. If we keep creating threads on an ad hoc basis, we may end up creating too many, which would hurt the application. Furthermore, if we try to create too many, the application may throw java.lang.OutOfMemoryError Exceptions.
So we need to improve further.
Executor Framework:
Java 5 brings executors along with Future and Callable/Runnable. It gives us control over how many threads we want to create and pool them.
With this, we can improve the above code as follows:

This is a considerable improvement in writing code, but we’re not there yet. The future’s mechanism is still quite complex. The get() call on it is still a blocking call. Although we are making an asynchronous call, in the end, we need a blocking call to get the value from the future.
The other thing is that it creates an opportunity for cache corruption. For example, if main threads submit tasks to the thread pool, the tasks would be executed by a thread from the pool. The main thread needs data, which is in another thread. These two threads may encounter different cores, potentially resulting in cache corruption. On top of that, the context switching from one core to another is also expensive.
Also, it needs the composability option that we like. So the code is much more imperative. Having imperative code is okay, but functional and declarative code is much more fun. So at least we could improve here; if we cannot do it in other places, that is alright.
So the next question would be, “What next from here?” How can we improve further?
Fork/Join Pool:
Java introduced the fork/join pool. It’s an implementation of the ExecutorService introduced by Java 5, as well as the executor framework. It fixes many of the problems we had with the old executor framework, like corrupted caches. In addition, it works on the idea that tasks that have just been made are likely to have a closer cache. That means newly created tasks should run on the same CPU, and older tasks may run on another CPU. Also, compared to other thread pool implementations, each thread in a fork/join pool keeps its own queue. Besides, the ForkJoin pool is implemented using a work-stealing algorithm. So if a thread in the pool finishes, it can steal from another thread’s queue from the tail of it. All of these provide us with performances to be proud of.
Let’s bring compossibility to the mixture
Java 8 introduces CompletableFuture on top of the fork/join pool. It includes the composition feature that we all enjoy; with this, we can rewrite the above code as follows:
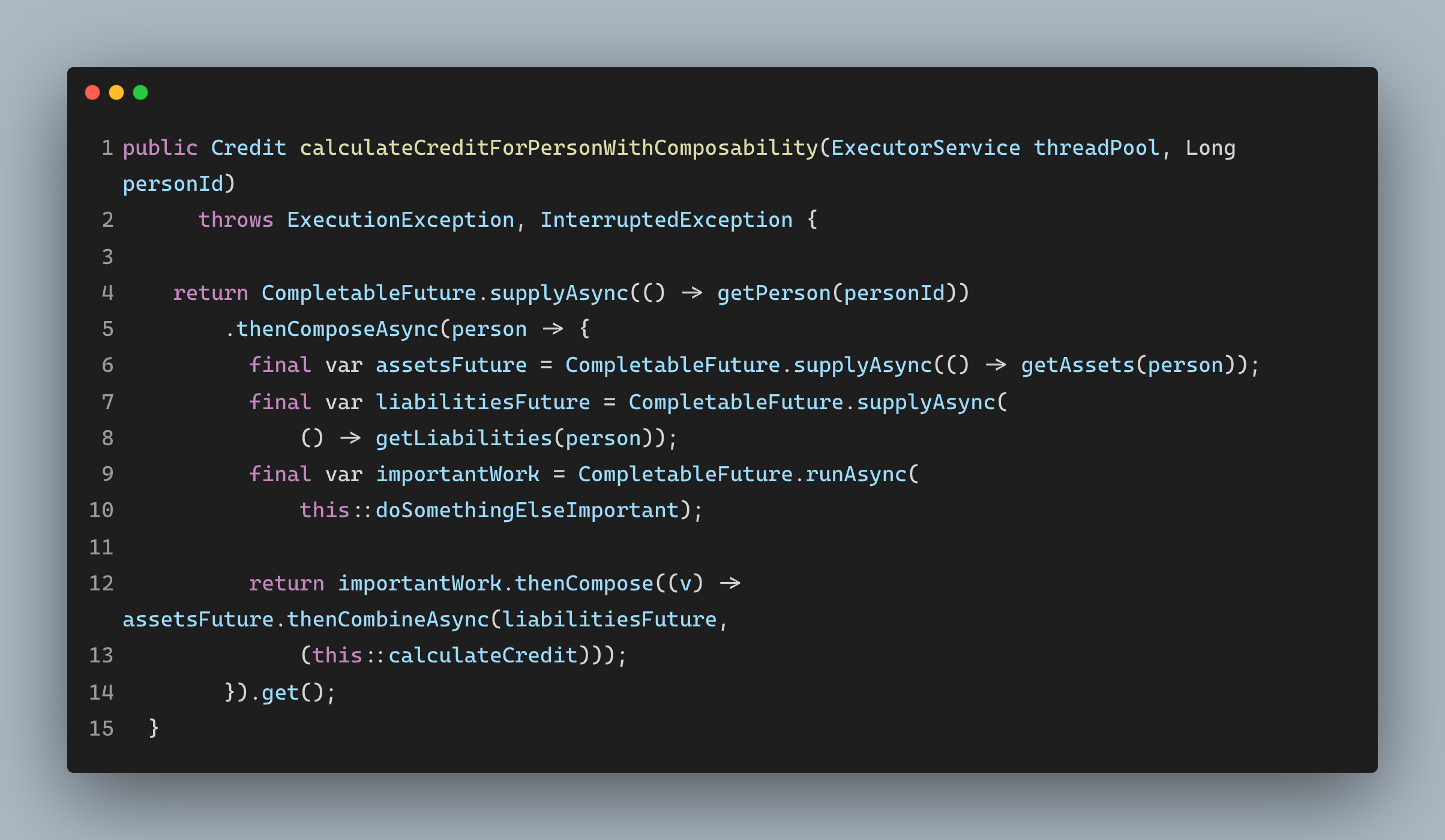
Reactive Java:
Well, this is great. We have gotten everything we wanted. This is improved performance with composability. However, there are some other alternatives to this on the market. Reactive frameworks like RxJava, Akka, Eclipse Vert.x, Spring WebFlux, Slick, etc., also give us performance and composability benefits. Let’s see an example of WebFlux.
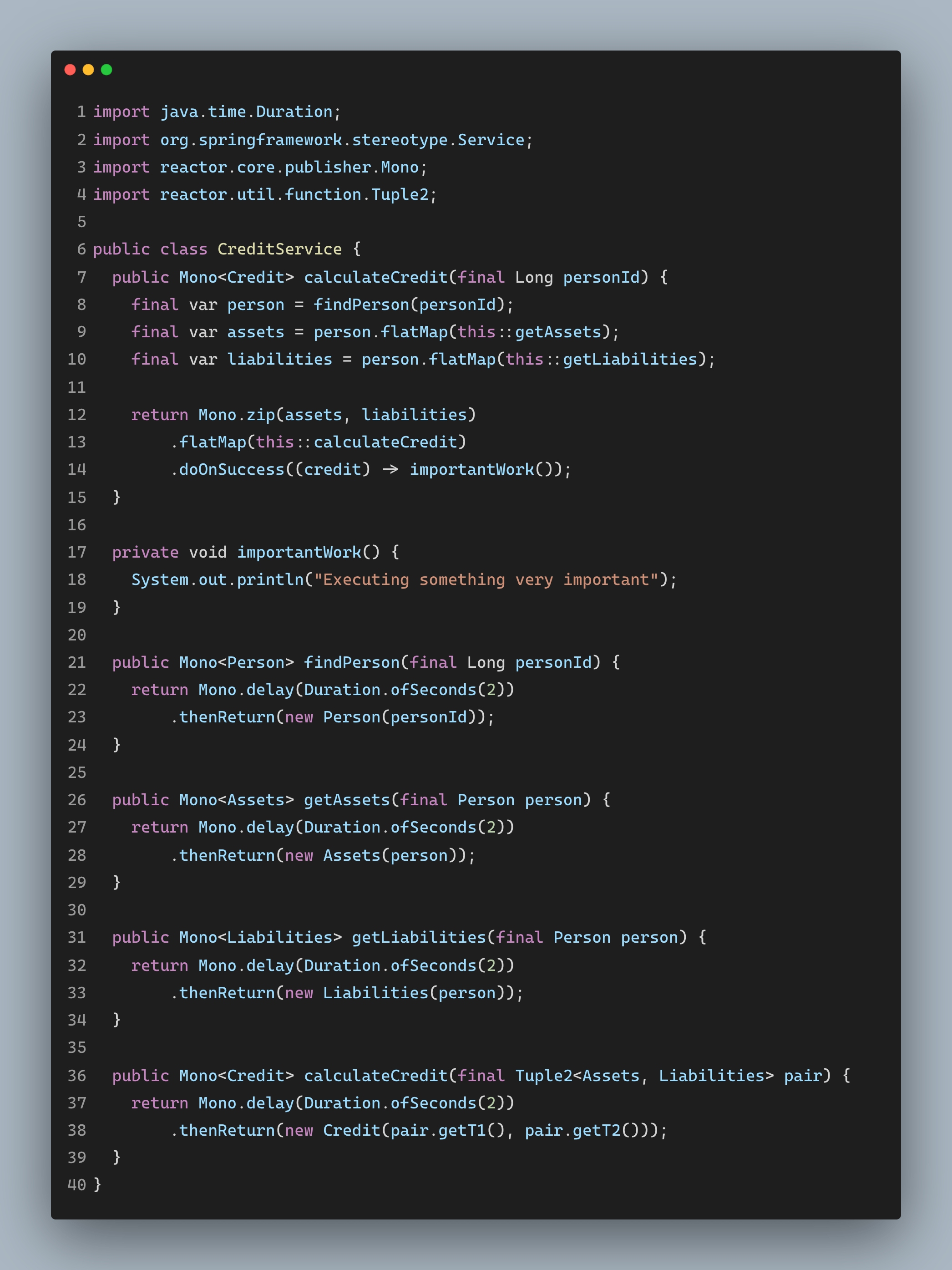
However, there are some drawbacks to these patterns as well. Here are a few examples:
- The learning curve of such a framework is quite stiff. Some of the patterns may seem mind-bending to the beginning.
- The cognitive load associated with these isn’t even an exaggeration. It hurts the code reading experience.
- The debugging of any problem is quite difficult. Since we don’t know what parts of the certain code are running on which threads, the path to accomplishing a task can be anything. And that’s why even the thread dump isn’t quite helpful.
- Also, it’s easy to overcomplicate things with these.
So what’s the solution?
Well, if we had the opportunity to go back to the imperative code we had at the beginning and the easy asynchronous functionality, that would be awesome. And that’s where Project looms comes into the picture.
Project Loom:
Project loom allows us to create as many threads as we want on an ad hoc basis without paying the penalty we had earlier. We don’t even care how many threads you want to create; we can, in fact, create millions of them. And they are cheap.
On top of that, we can have our imperative and blocking codes. So we don’t need to worry about blocking code at all.
Java 19 brings virtual threads; with that, we can have as much blocking code as we want.
If we want to use virtual threads, we can use the following executors:

The existing code for executors that we wrote earlier remains the same. Simply pass our newVirtualThreadPerTaskExecutor executor service. That’s it.
The virtual threads run on top of the classical threads, which are also called platform threads. These platform threads are basically threads in the fork/join pool. So by running a virtual thread, we get all the benefits that the fork/join pool brings.
In short, what virtual threads do is, when they see a blocking call, yield themselves from the running platform threads. The platform thread then keeps executing other virtual threads. Blocking calls usually happens when we call sleep or network operations. So when all these are done, the virtual thread can be resumed back to the platform thread to do the rest of the jobs.
By doing these, we are not wasting any of the threads’ time by being idle, but rather they are always busy working on something. On the other hand, the virtual thread is a Java construct that can be paused and resumed later without consuming extra CPU.
That makes our programming easy.
Conclusion
In conclusion, the blocking call was an enemy. To tackle this, we have invented many things; however, in the end, alongside all the inventions, we have come up with a new paradigm, which is a virtual thread, and with this, we no longer need to treat blocking calls as our enemy.
Rather, we can proudly invoke any blocking call, as many of them as we want.
That’s the story of two cities where blocking operations are treated differently. However, we have lots of bridges in between that make our life easy in many ways.


Author: A N M Bazlur Rahman
A N M Bazlur Rahman is a Software Engineer, Java Champion, Jakarta EE Ambassador, Author, Blogger, and Speaker. He has more than a decade of experience in the software industry, primarily with Java and Java-related technologies.
He enjoys mentoring, writing, delivering talks at conferences, and contributing to open-source projects. He is the founder and current moderator of the Bangladesh Java User Group. He is an editor for the Java Queue at InfoQ and Foojay.io.